- » Антропология
- » Археология
- » Архитектура
- » Астрономия
- » Библиотековедение
- » Биология
- » Биотехнологии
- » Ботаника
- » Ветеринария
- » Военные науки
- » География
- » Геология
- » Журналистика
- » За горизонтом современной науки
- » Зоология
- » Информационные технологии
- » Искусствоведение
- » История
- » Культурология
- » Лингвистика
- » Литература
- » Маркетинг
- » Математика
- » Машиностроение
- » Медицина
- » Менеджмент
- » Методика преподавания
- » Музыковедение
- » Нанотехнологии
- » Науки о Земле
- » Образование
- » Оптика
- » Педагогика
- » Политология
- » Правоведение
- » Психология
- » Регионоведение
- » Религиоведение
- » Сельское хозяйство
- » Социология
- » Спорт
- » Строительство
- » Телекоммуникации
- » Техника
- » Туризм
- » Управление и организация
- » Управление инновациями
- » Фармацевтика
- » Физика
- » Физическая культура
- » Филология
- » Философия
- » Химия
- » Экология
- » Экономика
- » Электроника
- » Электротехника
- » Юриспруденция
Разделы: Информационные технологии, Телекоммуникации
Размещена 09.07.2014. Последняя правка: 09.07.2014.
Просмотров - 8407
Расширенный алгоритм диагностики сетей на оборудовании Juniper
Лагутин Илья АнатольевичБакалавр Радиотехники
инженер-стажер филиала ЗАО «Энвижн Груп» Энвижн-Сибирь
Магистрант СибГУТИ
Консультант: Марамзин Валерий Валентинович, Ведущий инженер-конструктор Направление сетей и систем передачи данных NVision Group
УДК 004.722
Введение
Для мониторинга и крупных сетей (таких как сети ISP – Internet Service Provider или просто масштабных корпоративных локальных ресурсов) все острее ощущается нехватка универсального автоматизированного алгоритма поиска и устранения неисправностей, уменьшающего трудозатраты системных администраторов на обслуживание и выявление/устранение неполадок.
Целью статьи станет подробная конкретная реализация уже сформированного обобщенного алгоритма, применительно к оборудованию компании Juniper, но, имея достаточно подробный алгоритм, в котором нужно только применить соответствующие действия, конкретная реализация даже для гетерогенной сети не составит труда.
Опорной точкой станет обобщенная блок-схема алгоритма поиска и устранения неисправностей (траблшутинга) [1]
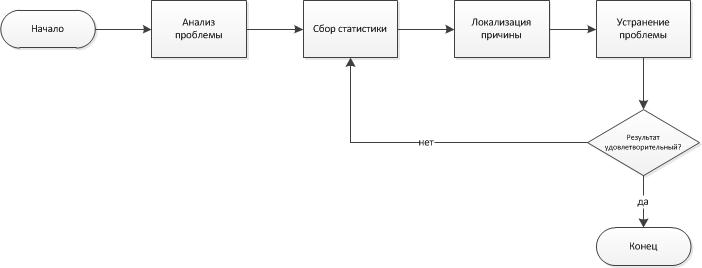
Рисунок 1. Обобщенный алгоритм поиска неисправностей
Имея некую структуру, можно, отталкиваясь от каждого составляющего блока, сформировать реальные последовательности действий, выполнение которых приведет к разрешению любой внештатной ситуации. (И чем подробнее и разветвленнее будет алгоритм, тем больше гарантий разрешения именно любой внештатной ситуации). Так же, хотелось бы отметить, что для рассматриваемых сетей (будь то сети ISP или крупные корпоративные сети), в которых будет использоваться такой алгоритм, при возникновении любого масштаба неисправности, счет времени на ее устранение идет на минуты. Для интернет-провайдера это заявленное время простоя, аптайма оборудования. Для корпоративных сетей это, в первую очередь, убытки, исчисляемые порой даже миллионами из-за незаключенных сделок или потерянного крупного партнера/клиента. Разумеется, для таких ситуаций предусматриваются резервные каналы, оборудование и целые ветки маршрутов, но никто не застрахован от случайностей.
Таким образом, разрабатываемый алгоритм должен эффективно работать как на крупных сетях с большим количеством узлов, максимально быстро выполняя свои функции, так и на более мелких сетевых структурах, для которых можно также по итогам анализа предоставлять некоторые рекомендации по развитию и резервированию.
Анализ проблемы, Сбор статистики
В виду выше оговорённых условий быстродействия алгоритма, предлагается объединить первые два этапа начальной модели, дабы эффективно и в кратчайшие сроки произвести все необходимые опросы и перейти непосредственно к устранению проблемы по возможности, а в противном случае выдать список рекомендаций к действию обслуживающего персонала.
Данный этап должен включать в себя следующие процессы:
- Первичный опрос каждого узла сети на предмет установления факта физической доступности. Это означает, что с начального корневого узла будут опрошены поочередно каждый элемент сети посредством команды ping.
- Если будет обнаружено не отвечающее устройство, его доступность необходимо проверить путем попытки зайти на него (telnet, ssh) совместно с опросом соседних с ним устройств на предмет доступности интерфейсов неисправного устройства.
- Если попытки зайти на проблемный узел сети оказались безуспешными, а опрос интерфейсов устройства с соседних ему узлов показывает их недоступность [2], с большой долей вероятности этот узел сети вышел из строя и на нем как минимум отсутствует питание. Это означает, что ремонт и диагностику необходимо производить физически на месте, завершение работы алгоритма.
Локализация причины
Если все устройства доступны, их интерфейсы функционируют, но работа сети осуществляется некорректно, следовательно, проблемы либо с маршрутизацией, либо с конфигурацией одного или нескольких узлов сети. Отсюда вытекает необходимость локализовать неисправный участок и выяснить ключевое устройство, после взаимодействия с которым механизм транспортировки трафика нарушается. В таком случае необходимо опираться на факты последствий неисправности, по которым можно определить проблемный участок. Это может означать как поступающие жалобы пользователей определенной подсети, так и результат наблюдений сети с помощью утилит мониторинга, которые достоверно методом SNMP опроса покажут неисправные узлы.
Касательно же автоматизации процесса, приемлемо использование команды traceroute, которая будет как сканер запущена алгоритмом последовательно с различных узлов сети к наиболее удаленным, тем самым будет выяснен участок сети, на котором возникает непроходимость трафика. [3]
Устранение проблемы
Локализовав, таким образом, неисправный участок, процесс переходит к следующему этапу решения возникшей неисправности, а именно – ее устранению. Это наиболее обширный блок алгоритма, который включает в себя следующие пункты:
- Один из интерфейсов может быть отключен логически, т.е. административно находиться в состоянии down. Проверка осуществляется командой run show interfaces terse. Значение параметров Admin и Link , указывающих на физическую и административную доступность интерфейсов, должно быть Up. В противном случае, если значение параметра Admin = Down, соответственно интерфейс по каким-то причинам отключен административно и его работу необходимо возобновить командой delete interfaces <InterfaceName> disable (выполняется из конфигурационного режима) .Если же параметр Link = Down, то в таком случае, речь идет о физической неисправности канала связи. Выдается соответствующее информационное сообщение.
- Если аппаратно маршрутизирующее устройство работает исправно, значит, нарушение функционирования касается только логики работы его программной части – конфигурации. В таком случае, проверке подлежит именно конфигурация устройства, которая, как правило, является типовой в крупных сетях. Это означает, что с небольшими различиями в адресах и логических связях, структура конфигурации каждого маршрутизатора фактически одинакова, т.к. реализуемая схема маршрутизации обеспечивается функционированием соответствующих протоколов, настройка которых в каждом устройстве является регламентированной процедурой. Другими словами, первым делом по шаблону проверяются настройки ключевых разделов конфигурации маршрутизаторов – protocols, routing-options, policy-options, interfaces., где все должно быть приведено к стандартному шаблону, а адресация верна. [4]
Таким образом, начальный алгоритм (рис.1) приобретает расширенный вид. (рис.2) где:
Блок 1 - процедура опроса каждого узла сети командой ping
Блок 2 - процедура проверки маршрутов сети между крайними точками командой traceroute
Блок 3,5 - условие-проверка недостижимых/недоступных устройств
Блок 4,6 - условие-проверка выхода из цикла сканирования
Блоки 1,3,4 и 2,5,6 объединены в условную процедуру проверки удаленной доступности узлов сети ping и traceroute соответственно
Блок 7 - процедура авторизации на потенциально нефункционирующее устройство
Блок 8 - условие-проверка успешности авторизации
Блок 11 - вывод сообщения при условии удаленной недоступности устройства
Блок 9 - процедура проверки работоспособности интерфейсов
Блок 12 - условие-проверка функционирования всех интерфейсов
Блок 13 - условие-проверка вида недоступности интерфейса (административно или физически)
Блок 10 - активация интерфейса в случае административного отключения интерфейса
Блок 14 - вывод сообщения о физических проблемах канала связи данного интерфейса
Блок 15 - проверка раздела конфигурации protocols путем сравнения с образцом и проверки правильности настройки логики функционирования
Блок 16 - проверка раздела конфигурации routing-options путем сопоставления с образцом, выявления ошибочных маршрутов.
Блок 17 - проверка раздела конфигурации policy-options путем сопоставления с образцом, проверки правильности функционирования логики настроенных фильтров
Блок 18 - условие-проверка наличия ошибок конфигурации в вышеупомянутых разделах
Блок 19 - процедура внесения изменений в соответствии с обнаруженными несоответствиями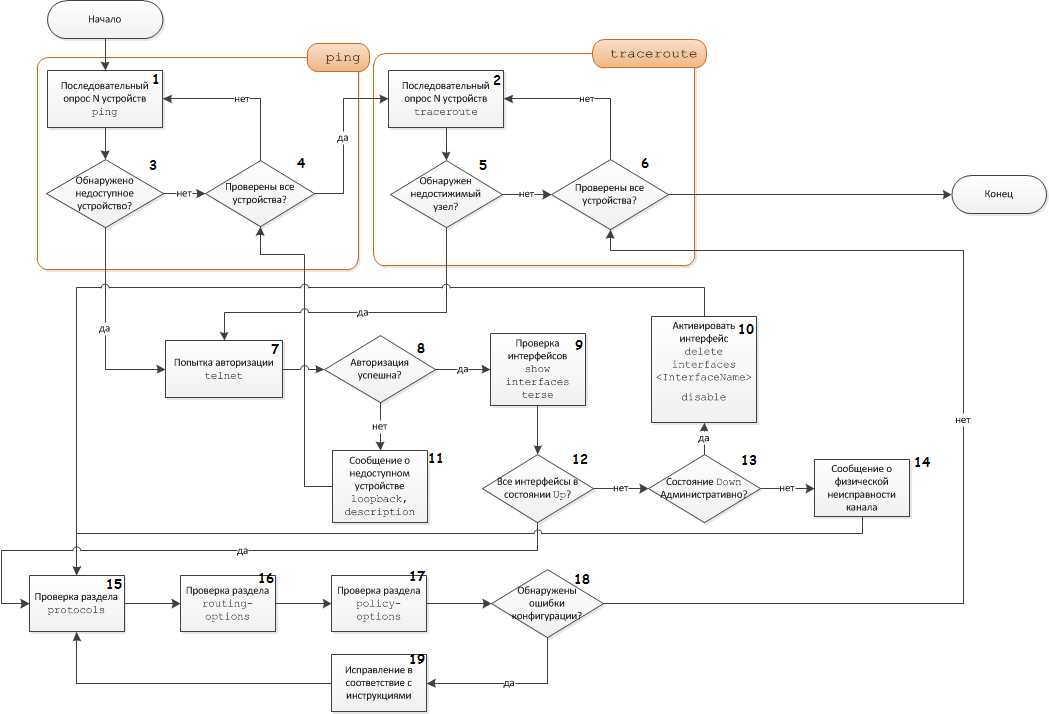
Рисунок 2. Расширенный алгоритм диагностики сетей
Рекомендуется для своевременного обнаружения и диагностирования проблем сети провести первоначальный ее аудит, составить полную топологию сети с точной адресацией узлов.
Заключение
Ни одна сеть, вне зависимости от ее масштабов, не может быть настроена и запущена сразу без последующей отладки. Более того, процесс настройки и конфигурирования сети может занимать очень длительное время, т.к. функционирование обеспечивается множеством составляющих протоколов, которые взаимодействуют друг с другом в разных комбинациях по-разному. И таких вариантов взаимодействия может возникнуть очень много и учесть их перед запуском сети не представляется возможности.
Именно по этой причине отладка сети производится непосредственно в процессе ее эксплуатации, вследствие чего неминуемы возникновения неполадок: начиная от выявления потенциально неустойчивых участков сети и заканчивая логическими ошибками конфигурации, всплывающими в ходе работы.
Учитывая тот факт, что данные проблемы зачастую проявляются уже в процессе эксплуатации сети, а отказы и долгие простои недопустимы, разработан алгоритм автоматической диагностики и устранения неисправностей, который анализирует размещенную сеть, решает или предлагает альтернативные варианты в случае невозможности разрешить возникшую неполадку. Существующие методологии недостаточно точны и слишком абстрактны, подразумевая, что вся работа по анализу и процедуре наладки возлагается на плечи обслуживающего персонала. Таким образом, обобщенные алгоритмы отредактированы и конкретизированы, но в то же время, делается упор на универсальность разрабатываемого алгоритма. В будущем предполагается работа над дальнейшим расширением с максимально большим количеством учета самых разных ситуаций и обстоятельств.
Конкретная реализация возможна на языках VBScript или JavaScript [5], которые просты и удобны для данной цели, а также присутствует возможность использовать написанные скрипы в терминальных программах.
1. Troubleshooting Overview http://www.cisco.com/en/US/docs/internetworking/troubleshooting/guide/tr1901.html
2. Resolution Guide - EX - Verify/Troubleshoot Physical Interface http://kb.juniper.net/InfoCenter/index? page=content&id=KB19797
3. Network Troubleshooting Tools http://oreilly.com/catalog/nettroubletools/chapter/ch04.html
4. Junos Intermediate Routing Instructor Guide, Revision 12.a
5. Example Scripts for SecureCRT® for Windows http://www.vandyke.com/support/securecrt/scripting_examples.html
Рецензии:
9.07.2014, 16:32 Каменев Александр Юрьевич
Рецензия: Техническая диагностика вычислительных сетей является важным направлением повышения их надёжности, поэтому статья имеет актуальное значение . Как для студенческой или магистрантской работы статья имеет достаточный исследовательский уровень. Однако следует выделить следующие её недостатки: непонятен термин "модель алгоритма" - следовало бы его заменить на "блок-схема алгоритма" или просто "алгоритм" (см. рис. 1, 2); необходимо дать более подробное описание блоков алгоритмов (предварительно пронумеровав их, введя потом описание каждого из них с ссылкой на номер); следует обобщённо, но чётко указать вклад автора в заключительной части. Необходимо также уточнить или изменить название статьи, заменив в ней слово "модель" на "алгоритм". После устранения замечаний статься рекомендуется к публикации.
Исправлено с учетом замечаний. Спасибо
22.07.2014, 16:21 Ляпунова Ирина Артуровна
Рецензия: Довольно квалифицированно написанная статья. Однако маловероятно, что ранее никто не пытался написать универсальный алгоритм "поиска и устранения неисправностей, уменьшающего трудозатраты системных администраторов на обслуживание и выявление/устранение неполадок". В будущем рекомендую приводить сравнение работы алгоритмов и всех своих научных результатов с популярными и/или зарубежными. Статья рекомендуется к публикации.
29.08.2014, 0:04 Назарова Ольга Петровна
Рецензия: Рекомендуется к печати.
Комментарии пользователей:
|
9.07.2014, 13:17 Зайцев Владислав Валерьевич Отзыв: Статья агонь, продолжай рисовать |
Оставить комментарий
|
E-mail: sci@sci-article.ru
©2013-2023 Электронный периодический научный журнал SCI-ARTICLE.RU Любое использование размещённых на сайте журнала статей и материалов возможно только с обязательной активной ссылкой на сайт журнала «SCI-ARTICLE.RU».
|
Вверх